使用不安全的 Python 将速度提高 100 倍
我们将使用 “不安全的 Python “把一些 numpy 代码的速度提高 100 倍。它与不安全的 Rust 并不完全相同,但有点类似,我不知道还能叫它什么……你会明白的。这不是你在大多数 Python 代码中都会用到的东西,但偶尔用起来还是很方便的,而且我认为它从一个有趣的角度展示了 “Python 的本质”。
假设你用 pygame 用 Python 写了一个简单的游戏。
(pygame 是当今的主流吗?我不是问这个问题的人;值得称赞的是,它有一个非常简单的屏幕/鼠标/键盘 API,而且由于它是构建在 SDL 之上的,所以相当便携。它可以在主要的桌面平台上运行,稍加改动,还可以使用 Buildozer 在 Android 上运行。无论如何,pygame 只是 “不安全 Python “可以解决问题的一个真实例子(译者注:pygame 是一种不安全的 Python)。
我们再假设你经常调整图片大小,所以想优化一下。于是你发现了一个不足为奇的事实:OpenCV 的大小调整速度比 pygame 快,下面是一个简单的微基准测试:
from contextlib import contextmanager
import time
@contextmanager
def Timer(name):
start = time.time()
yield
finish = time.time()
print(f'{name} took {finish-start:.4f} sec')
import pygame as pg
import numpy as np
import cv2
IW = 1920
IH = 1080
OW = IW // 2
OH = IH // 2
repeat = 100
isurf = pg.Surface((IW,IH), pg.SRCALPHA)
with Timer('pg.Surface with smoothscale'):
for i in range(repeat):
pg.transform.smoothscale(isurf, (OW,OH))
def cv2_resize(image):
return cv2.resize(image, (OH,OW), interpolation=cv2.INTER_AREA)
i1 = np.zeros((IW,IH,3), np.uint8)
with Timer('np.zeros with cv2'):
for i in range(repeat):
o1 = cv2_resize(i1)
这会打印出:
pg.Surface with smoothscale took 0.2002 sec np.zeros with cv2 took 0.0145 sec
你被 mircobenchmark 报告的 13 倍速度所吸引,回到你的游戏中,使用 pygame.surfarray.pixels3d 以零拷贝方式访问 numpy 数组中的像素。你满怀希望地将此数组传递给 cv2.resize,结果发现一切都慢了很多。真该死!”你想,”缓存 “什么的。永远不要相信 mircobenchmark!”
总之,为了以防万一,你在 mircobenchmark 中的 pixels3d 数组上调用了 cv2.resize。也许速度变慢的现象会重现?
i2 = pg.surfarray.pixels3d(isurf)
with Timer('pixels3d with cv2'):
for i in range(repeat):
o2 = cv2_resize(i2)
果然,速度非常慢,就像你在大型程序中看到的一样:
pixels3d with cv2 took 1.3625 sec
因此比 smoothscale 慢 7 倍,更令人震惊的是,比使用 numpy.zeros 调用的 cv2.resize 慢近 100 倍!这到底是怎么回事?比如,我们有两个相同形状和数据类型的零初始化 numpy 数组。当然,调整后的输出数组也具有相同的形状和数据类型:
print('i1==i2 is', np.all(i1==i2))
print('o1==o2 is', np.all(o1==o2))
print('input shapes', i1.shape,i2.shape)
print('input types', i1.dtype,i2.dtype)
print('output shapes', o1.shape,o2.shape)
print('output types', o1.dtype,o2.dtype)
正如你所期望的那样,这意味着一切都一样:
i1==i2 is True
o1==o2 is True
input shapes (1920, 1080, 3) (1920, 1080, 3)
input types uint8 uint8
output shapes (960, 540, 3) (960, 540, 3)
output types uint8 uint8一个函数在一个数组上的运行速度怎么会比在另一个看似相同的数组上慢 100 倍呢?我的意思是,你会希望 SDL 不会把像素分配到某个访问速度特别慢的 RAM 区域,尽管理论上它可以做到这一点,只要内核提供一点帮助(比如创建一个不可缓存的内存区域之类的)。不会是这样吧?- 是不是有什么我没注意到的可怕的内存一致性协议?如果不是,如果两个阵列的内存形状和大小都一样,那有什么不同会让我们的速度降低 100 倍?
事实证明…我承认,我是在放弃这个问题1 并转而研究其他问题之后才偶然发现的。完全是偶然的,那件事情涉及到将 numpy 数据传递给 C 代码,所以我不得不从 C 代码中学习这些数据的样子:
print('input strides',i1.strides,i2.strides)
print('output strides',o1.strides,o2.strides)
啊,跨步。在输出数组中是一样的,但在输入数组中却截然不同:
input strides (3240, 3, 1) (4, 7680, -1) output strides (1620, 3, 1) (1620, 3, 1)
我们将看到,步长之间的这种差异实际上完全导致了 100 倍的减速。我们能解决这个问题吗?我们可以,但首先,帖子本身需要严重减速来解释这些步长,因为它们太奇怪了。然后,我们再从这些该死的步长中抢回我们的 100 倍。
numpy 数组内存布局
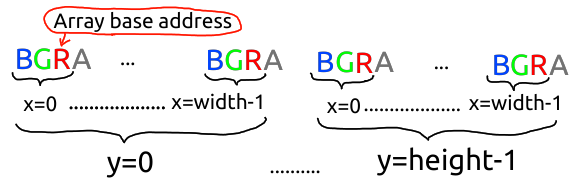
那么,什么是 “stride”?stride告诉你从一个像素到下一个像素需要多少字节。例如,假设我们有一个三维数组,比如 RGB 图像。那么在给定数组基指针和 3 个跨距的情况下,array[x,y,z]的地址将是 base + x*xstride + y*ystride + z*zstride(在图像中,z 是 0、1 或 2 之一,表示 RGB 图像的 3 个通道)。
换句话说,步长定义了数组在内存中的布局。无论好坏,numpy 对于这种布局都非常灵活,因为对于给定的数组形状和数据类型,它支持多种不同的stride 值。
手头的两种布局–numpy 的默认布局和 SDL 的布局–是……嗯,我甚至不知道这两种布局中哪一种更让我反感。从 stride 值可以看出,numpy 默认使用的三维数组布局是 base + x*3*height + y*3 + z。

这意味着一个像素的 RGB 值存储在 3 个相邻的字节中,而一列的像素则连续存储在内存中,即列主序。我觉得这很令人反感,因为传统上图像都是按行-主顺序存储的,特别是图像传感器是这样发送图像的(也是这样捕捉图像的,正如你从滚动快门中看到的那样–每一行都是在稍有不同的时间捕捉到的,而不是列)。
“基于 numpy 的流行图像库说:”为什么,我们也遵循这一受人尊敬的传统呢?”你自己看–将形状数组(1920,1080)保存为 PNG 文件,你就会得到一张 1080×1920 的图像。”这是事实,当然也会让情况变得更糟:如果使用 arr[x,y] 进行索引,那么 x(又称零维)实际上对应的是相应 PNG 文件中的垂直维度,而 y(又称一维)对应的是水平维度。因此,numpy 数组的列对应于 PNG 图像的行。这使得 numpy 图像布局在某种意义上成为 “行主要 “布局,但 x 和 y 的含义却与通常相反。
……除非你的 numpy 数组来自 pygame 的曲面对象,在这种情况下,x 确实是水平维度的索引。因此,用 imageio 保存 pixels3d(surface),相对于 pygame.image.save(surface) 创建的 PNG,会产生一个转置的 PNG。如果还觉得不够过瘾,cv2.resize 会获取一个(宽度、高度)元组作为目标尺寸,生成一个形状为(高度、宽度)的输出数组。
在这些侮辱和伤害的背景下,SDL 有一个诱人的、看起来很文明的布局,其中 x 是 x,y 是 y,数据以诚实的行大顺序存储,符合 “行 “的所有含义。但仔细一看,它的布局却践踏了我的感情:基数 + x*4 + y*4* 宽度 – z。
比如,在 RGB 图像中,步长为 4,而不是预期的 3,这一点我可以理解。当我们将 SRCALPHA 传递给曲面构造函数时,我们确实要求得到一个带有 alpha 通道的 RGBA 图像。因此,我猜它会将 alpha 通道与 RGB 像素保存在一起,而步长中的 4 是跳过 RBGA 中的 As 所必需的。但我想问的是,为什么要有单独的 pixels3d 和 pixels_alpha 函数?在使用带有 pygame 表面的 numpy 时,要分别处理 RGB 和字母总是很烦人。为什么不使用一个 pixels4d 函数呢?
不过好吧,4 而不是 3 我还能接受。但是-1的z值?减一?你从红色像素的地址开始,为了得到绿色像素,你往回走了一个字节?你这是在耍我。
事实证明,SDL 同时支持 RGB 和 BGR 布局(特别是,显然从文件加载的曲面是 RGB,而在内存中创建的曲面是 BGR?)如果使用 pygame 的应用程序接口,就不必担心 RGB 和 BGR 的问题,应用程序接口会透明地处理这些问题。如果你使用 pixels3d 与 numpy 交互,你也不必担心 RGB 与 BGR 之争,因为 numpy 在跨距方面的灵活性,可以让 pygame 给你一个看起来像 RGB 的数组,尽管它在内存中是 BGR。为此,z stride 设置为-1,数组的基指针指向第一个像素的红色值–比数组内存开始的位置提前两个像素,也就是第一个像素的蓝色值所在的位置。
等等……现在我明白为什么我们有 pixels3d 和 pixels_alpha 却没有 pixels4d 了!因为 SDL 有 RGBA 和 BGRA 图像(BGRA,而不是 ABGR),而且无论你使用什么奇怪的跨距值,都无法使 BGRA 数据看起来像 RGBA numpy 数组。布局的灵活性是有限度的……或者说,除了可计算性的限度之外,真的没有任何限度,但幸好 numpy 停止了可配置的步长,而且不会让你指定一个通用回调函数 addr(base, x, y, z) 来实现完全可编程的布局2。
因此,为了透明地支持 RGBA 和 BGRA,pygame 不得不为我们提供两个 numpy 数组:一个用于 RGB(或 BGR,取决于曲面),另一个用于 Alpha。这些 numpy 数组具有正确的形状,可以让我们访问正确的数据,但它们的布局却与普通数组的形状大相径庭。
而不同的内存布局绝对可以解释性能上的重大差异。我们可以尝试找出性能差异几乎达到 100 倍的确切原因。但在可能的情况下,我更愿意直接清除垃圾,而不是详细研究。因此,与其深入研究,我们不如简单地证明布局差异确实导致了 100 倍的性能差异,然后在不改变布局的情况下消除性能下降,这就是 “不安全 Python “的最终作用。
我们怎样才能证明是布局本身,而不是 pygame Surface 数据的其他属性(如分配的内存)导致了速度变慢?我们可以在自己创建的 numpy 数组上对 cv2.resize 进行基准测试,该数组的布局与 pixels3d 给出的布局相同:
# create a byte array of zeros, and attach
# a numpy array with pygame-like strides
# to this byte array using the buffer argument.
i3 = np.ndarray((IW, IH, 3), np.uint8,
strides=(4, IW*4, -1),
buffer=b'\0'*(IW*IH*4),
offset=2) # start at the "R" of BGR
with Timer('pixels3d-like layout with cv2'):
for i in range(repeat):
o2 = cv2_resize(i3)
事实上,这也是我们在 pygame Surface 数据中测得的最慢速度:
pixels3d-like layout with cv2 took 1.3829 sec
出于好奇,我们可以检查一下如果只是在这些布局之间复制数据会发生什么情况:
i4 = np.empty(i2.shape, i2.dtype)
with Timer('pixels3d-like copied to same-shape array'):
for i in range(repeat):
i4[:] = i2
with Timer('pixels3d-like to same-shape array, copyto'):
for i in range(repeat):
np.copyto(i4, i2)
赋值运算符和 copyto 的速度都很慢,几乎和 cv2.resize 一样慢:
pixels3d-like copied to same-shape array took 1.2681 sec pixels3d-like to same-shape array, copyto took 1.2702 sec
让代码运行得更快
我们能做些什么呢?我们无法改变 pygame Surface 数据的布局。而且我们也不想复制 cv2.resize 的 C++ 代码及其各种特定平台的优化,看看能否在不降低性能的情况下将其调整为 Surface 布局。我们可以做的是,使用具有 numpy 默认布局的数组(而不是直接传递 pixel3d 返回的数组对象)将 Surface 数据输入 cv2.resize。
当然,这并不是说在任何给定函数中都有效。但它特别适用于调整大小,因为它并不真正关心数据的某些方面,而我们将顺便公然歪曲这些方面:
- 如果你给它 BGR 数据并谎称它是 RGB,代码会产生与实际 RGB 数据相同的结果。
- 同样,在调整大小时,哪一个数组维度代表宽度,哪一个代表高度并不重要。
现在,我们再来看看 pygame 的 BGRA 数组形状(height, width)的内存表示。
这种表示法实际上与使用 numpy 默认跨距的 RGBA 形状(height, width)数组相同!我的意思是,并非如此–如果我们将此数据重新解释为 RGBA 数组,我们就会将红色通道值视为蓝色通道值,反之亦然。同样,如果我们用 numpy 的默认步长将此数据重新解释为(height, width)数组,我们就会隐式地将图像转置。但调整大小并不重要!
而且,作为额外的奖励,我们将获得一个 RGBA 数组,只需调用一次 cv2.resize 即可调整其大小,而无需分别调整 pixels3d 和 pixels_alpha 的大小。太棒了
下面的代码获取了一个 pygame 曲面,并返回了底层 RGBA 或 BGRA 数组的基指针,以及一个标志,告诉我们它是 BGR 还是 RGB:
import ctypes
def arr_params(surface):
pixels = pg.surfarray.pixels3d(surface)
width, height, depth = pixels.shape
assert depth == 3
xstride, ystride, zstride = pixels.strides
oft = 0
bgr = 0
if zstride == -1: # BGR image - walk back
# 2 bytes to get to the first blue pixel
oft = -2
zstride = 1
bgr = 1
# validate our assumptions about the data layout
assert xstride == 4
assert zstride == 1
assert ystride == width*4
base = pixels.ctypes.data_as(ctypes.c_void_p)
ptr = ctypes.c_void_p(base.value + oft)
return ptr, width, height, bgr
现在,我们有了指向像素数据的底层 C 指针,可以将其封装在一个具有默认跨度的 numpy 数组中,隐式地对图像进行转置并交换 R 和 B 通道。一旦我们在输入和输出数据中都 “附加 “了一个具有默认跨度的 numpy 数组,我们调用 cv2.resize 的速度就会快 100 倍!
def rgba_buffer(p, w, h):
# attach a WxHx4 buffer to the base pointer
type = ctypes.c_uint8 * (w * h * 4)
return ctypes.cast(p, ctypes.POINTER(type)).contents
def cv2_resize_surface(src, dst):
iptr, iw, ih, ibgr = arr_params(src)
optr, ow, oh, obgr = arr_params(dst)
# our trick only works if both surfaces are BGR,
# or they're both RGB. if their layout doesn't match,
# our code would actually swap R & B channels
assert ibgr == obgr
ibuf = rgba_buffer(iptr, iw, ih)
# numpy's default strides are height*4, 4, 1
iarr = np.ndarray((ih,iw,4), np.uint8, buffer=ibuf)
obuf = rgba_buffer(optr, ow, oh)
oarr = np.ndarray((oh,ow,4), np.uint8, buffer=obuf)
cv2.resize(iarr, (ow,oh), oarr, interpolation=cv2.INTER_AREA)
果然,在 Surface 数据上使用 cv2.resize,速度不降反升,与调整 RGBA numpy.zeros 数组的大小一样快(我们最初的基准是 RGB 数组,而不是 RGBA):
osurf = pg.Surface((OW,OH), pg.SRCALPHA)
with Timer('attached RGBA with cv2'):
for i in range(repeat):
cv2_resize_surface(isurf, osurf)
i6 = np.zeros((IW,IH,4), np.uint8)
with Timer('np.zeros RGBA with cv2'):
for i in range(repeat):
o6 = cv2_resize(i6)
基准显示,我们的回报是 100 倍:
attached RGBA with cv2 took 0.0097 sec np.zeros RGBA with cv2 took 0.0066 sec
上面所有难看的代码都在 GitHub 上。由于代码很丑,你无法确定它是否真的能正确调整图片大小,所以那里还有一些代码可以测试非零图片的大小调整。如果运行它,你会得到以下华丽的输出图像:

我们的速度真的提高了 100 倍吗?这取决于你如何计算。我们让 cv2.resize 的运行速度比直接调用 pixel3d 数组快 100 倍。但具体到调整大小,pygame 有 smoothscale,我们的速度是它的 13-15 倍。除了 resize 之外,GitHub 上还有一些其他函数的基准测试,其中有些函数没有相应的 pygame API:
- 用 dst[:] = src 复制:28 倍
- 用 dst[:] = 255 – src 反转:24 倍
- cv2.warpAffine: 12 倍
- cv2.medianBlur: 15x
- cv2.GaussianBlur: 200x
所以并不是 “精确 “的 100 倍,不过我觉得称之为 “100 倍 “也足够公平。
无论如何,如果有那么多人在 Python 中使用 SDL,我会很惊讶这个特定的问题是否具有广泛的相关性。但我猜想,具有奇怪布局的 numpy 数组也会出现在其他地方,所以这种技巧可能与其他地方相关。
“不安全的 Python
上面的代码使用了 “C 语言的知识 “来提高速度(Python 通常会对你隐藏数据布局,而 C 语言则会自豪地公开数据布局),但不幸的是,它也有 C 语言的内存(不)安全问题–我们得到了一个指向像素数据的 C 语言基本指针,从这一点出发,如果我们弄乱了指针运算,或者在数据已经释放后使用它,我们就会崩溃或损坏数据。但我们没有编写任何 C 代码,全部是 Python 代码。
Rust 有一个 “unsafe”(不安全)关键字,编译器会强制你意识到,你调用的 API 会使正常的安全保证失效。但 Rust 编译器不会因为你在函数中使用了不安全代码块,就把你的函数标记为 “不安全”。相反,编译器会让你自己决定你的函数本身是否不安全。
(在我们的示例中,cv2_resize_surface 是一个安全的 API,假设我没有 bug,因为没有任何恐怖代码会逃逸到外部世界–在外部,我们只看到输出表面被输出数据填满。但 arr_params 是一个完全不安全的 API,因为它返回的是一个 C 指针,你可以用它做任何事情。rgba_buffer 也是不安全的–虽然我们返回的是一个 numpy 数组,一个 “安全 “对象,但并不妨碍在释放数据后使用它。在一般情况下,任何静态分析都无法判断你是否从不安全的构建模块中构建了安全的东西。
Python 没有 unsafe 关键字–这对于静态注释稀少的动态语言来说是很正常的。但除此之外,Python + ctypes + C 库在精神上有点类似于带有不安全的 Rust。这种语言默认情况下是安全的,但当你需要它时,你可以使用它。
“不安全的 Python “体现了一个普遍原则:Python 中有很多 C 语言。C 是 Python 邪恶的孪生兄弟,或者,按照时间顺序,Python 是 C 善良的孪生兄弟。C 给你提供的是性能,并不关心可用性或安全性;如果有任何脚枪走火,请告诉你的医疗服务提供者,C 并不感兴趣。另一方面,Python 给你的是安全性,它基于十年来对初学者可用性的研究。但它并不关心性能。它们都是为了两个相反的目标而积极优化,其代价是忽略了对方的目标。
但除此之外,Python 从一开始就考虑到了 C 语言的扩展。如今,在我看来,Python 的功能就是为流行的 C/C++ 库提供一个打包系统。我从 C++ 中下载并构建 OpenCV 来使用它,远不如从 Python 中安装 OpenCV 二进制文件并使用它们,因为 C++ 没有标准的包管理系统,而 Python 有。有很多高性能库(例如在科学计算和深度学习领域)在 Python 中调用的代码比在 C/C++ 中调用的要多。另一方面,如果你希望 Python 代码得到认真优化,并且部署占用空间小/启动时间短,你可以使用 Cython 来生成一个 “如同用 C 语言编写 “的扩展,以避免使用像 numba 这样 “更 Pythonic “的基于 JIT 的系统的开销。
Python 中不仅有很多 C 语言的元素,而且它们是对立的,可以很好地互补。让 Python 代码变得更快的一个好方法就是以正确的方式使用 C 库。相反,安全使用 C 的好方法是用 C 编写核心,用 Python 编写核心之上的大量逻辑。Python 与 C/C++/Rust 的组合–要么是一个带有大量 Python 扩展 API 的 C 程序,要么是一个用 C 完成所有繁重工作的 Python 程序–似乎在高性能、数字、桌面/服务器领域占据了主导地位。虽然我不确定这一事实是否鼓舞人心,但我认为这是事实3,而且事情会长期这样发展下去。
感谢 Dan Luu 对本帖草稿的审阅。
P.S.
- 如果你只是为了好玩,或者只是在一个小团队里工作,就会出现这种情况。如果我是拿钱来做这件事的,我会一直研究下去,直到弄明白为止,至少如果团队足够大,不用担心这会耽误更重要的工作。这让人思考,虽然我不确定自己对这件事的看法。
- 值得庆幸的是,因为现有的布局灵活性 “只 “让我们的速度降低了 100 倍,而如果使用回调,速度很可能会达到 10000 倍。
- 我在这方面不是很在行,我很乐意听听更有经验的人的意见,看看现在该用什么来实现类似 Krita 或 Blender 的功能。我倾向于 “一个带有 C/C++/Rust 库的 Python 程序”,而不是 “一个带有 Python 扩展 API 的 C++/Rust 程序”,因为对于快速迭代一个庞大而复杂的代码库来说,C++ 太不安全,而 Rust 太安全–所以我想把大部分做很多小事情的代码保留在 Python 中,而把 C/C++/Rust 用于优化的生产代码,做一些容易理解的繁重工作。但这种结构化程序的方式最多只能算是中规中矩,我不知道自己是否遗漏了什么。
本文文字及图片出自 A 100x speedup with unsafe Python