你的程序实际上可以并行使用多少个 CPU 内核?
在运行 CPU 密集型并行程序时,通常需要根据机器上 CPU 内核的数量来确定线程或进程池的大小。线程数量少了,就无法充分利用所有内核;线程数量多了,程序运行速度就会开始变慢,因为多个线程会争夺同一个内核。反正理论上是这样。
那么,如何检查计算机有多少个内核?这个建议真的好吗?
事实证明,要确定运行多少个线程非常棘手:
- Python 标准库提供了多个 API 来获取这些信息,但都不够充分。
- 更糟的是,由于指令级并行和同步线程(又称 Intel CPU 上的超线程)等 CPU 特性,您能有效使用的内核数量取决于您编写的代码!
让我们来看看为什么计算程序可以使用多少个 CPU 内核如此困难,然后再考虑可能的解决方案。
用 Python 获取 CPU 内核数
如果阅读 Python 标准库文档,它有一个 os.cpu_count() 函数,可以返回 “系统中逻辑 CPU 的数量”。逻辑是什么意思?我们稍后再讨论。
文档还告诉你,”len(os.sched_getaffinity(0)) 可以获取当前进程的调用线程被限制使用的逻辑 CPU 数量”。调度器亲和性是一种限制进程使用特定内核的方法。
遗憾的是,这种应用程序接口也不够充分。例如,在 Linux 上,用于实现 Docker 和其他容器系统的 cgroups API 有多种限制 CPU 使用的方法。在这里,我们将 CPU 限制为 2.25 个内核:
$ docker run -i -t --cpus=2.25 python:3.12-slim Python 3.12.1 (main, Dec 9 2023, 00:21:37) [GCC 12.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import os >>> os.cpu_count() 20 >>> len(os.sched_getaffinity(0)) 20
实际上,我们只能使用 2.25 个 CPU,但两个应用程序接口都不知道这一点。
什么是逻辑 CPU?
操作系统选项只是问题的开端,在举例说明之前,我们需要了解什么是物理 CPU 内核和逻辑 CPU 内核。我的电脑使用的是英特尔 i7-12700K 处理器:
- 12 个物理内核(8 个高性能内核和 4 个性能较弱的内核)。
- 20 个逻辑内核。
现代 CPU 内核可以并行执行多条指令。但是,如果 CPU 在等待从 RAM 中加载某些数据时卡住了,会发生什么情况呢?在此之前,它可能无法执行任何工作。
为了利用这些可能被浪费的资源,CPU 物理内核会在操作系统面前假装成多个内核。在我的 CPU 上,8 个速度更快的内核可以假装成两个内核,总共有 16 个逻辑内核。成对的逻辑内核将共享同一个物理内核。如果一个逻辑内核没有充分利用所有内部算术逻辑单元,例如因为它在等待内存加载,那么通过配对逻辑内核运行的代码仍可使用这些闲置资源。
这种技术被称为同步多线程技术,英特尔公司称之为超线程技术。如果你有一台个人电脑,通常可以在 BIOS 中禁用它。
现在我们又有了一个新问题。抛开调度器亲和性等因素不谈,我们应该使用物理内核数还是逻辑内核数作为线程池大小?
一个令人尴尬的并行例子
让我们来看看用 Numba 编译成机器代码的两个函数。我们确保释放 GIL 以实现并行性。
这两个函数做同样的事情,但其中一个比另一个快得多。我们可以在多个线程上并行运行这些函数,理论上可以线性提高吞吐量,直到内核耗尽为止。
from numba import njit
import numpy as np
@njit(nogil=True)
def slow_threshold(img, noise_threshold):
noise_threshold = img.dtype.type(noise_threshold)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
result[i, j] = img[i, j] // 256
for i in range(result.shape[0]):
for j in range(result.shape[1]):
if result[i, j] < noise_threshold // 256:
result[i, j] = 0
return result
@njit(nogil=True)
def fast_threshold(img, noise_threshold):
noise_threshold = np.uint8(noise_threshold // 256)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
value = img[i, j] >> 8
value = (
0 if value < noise_threshold else value
)
result[i, j] = value
return result
我们将运行该函数处理图像,并测量其运行所需的时间:
rng = np.random.default_rng(12345)
def make_image(size=256):
noise = rng.integers(0, high=1000, size=(size, size), dtype=np.uint16)
signal = rng.integers(0, high=5000, size=(size, size), dtype=np.uint16)
# A noisy, hard to predict image:
return noise | signal
NOISY_IMAGE = make_image()
assert np.array_equal(
slow_threshold(NOISY_IMAGE, 1000),
fast_threshold(NOISY_IMAGE, 1000)
)
下面是在单核心上运行每个功能所需的时间:
%timeit slow_threshold(NOISY_IMAGE, 1000)
90.6 µs ± 77.7 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
和
%timeit fast_threshold(NOISY_IMAGE, 1000)
24.6 µs ± 10.8 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
扩展到多个线程
现在我们有了几个函数,我们将设置一种方法,利用线程池处理给定的图像列表:
from multiprocessing.dummy import Pool as ThreadPool
def apply_in_thread_pool(
num_threads, function, images
):
with ThreadPool(num_threads) as pool:
for image in images:
result = pool.map(
lambda img: function(img, 1000),
images
)
assert len(result) == len(images)
接下来,我们将使用 benchit 库(也可以使用 perfplot,但要注意它是 GPL 许可的)绘制不同线程数运行不同函数所需的时间图:
import benchit
benchit.setparams(rep=1)
# 400 images to run through the pool:
IMAGES = [make_image() for _ in range(400)]
def slow_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, slow_threshold, IMAGES)
def fast_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, fast_threshold, IMAGES)
# Measure the two functions with 1 to 24 threads:
timings = benchit.timings(
[slow_threshold_in_pool, fast_threshold_in_pool],
range(1, 25),
input_name="Number of threads"
)
timings.plot(logy=True, logx=False)
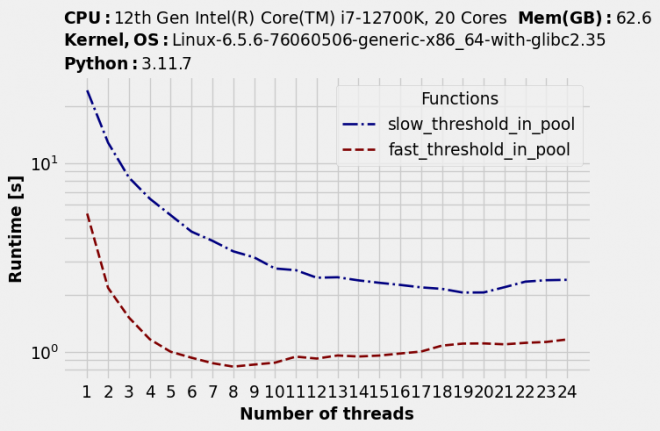
请注意运行时间是如何随着线程数的增加而缩短的……直到一个点。之后运行时间又开始变短。到目前为止,这正是我们所期望的。但也有出乎意料的地方:每个函数的最佳线程数都不同。
timings.to_dataframe().idxmin(axis="rows")
| 函数 | 最佳线程数 |
|---|---|
| slow_threshold | 19 |
| fast_threshold | 8 |
并行性的最佳效果也取决于你的代码
我们的慢速函数基本上可以利用所有逻辑内核。可能它没有充分利用特定物理内核的所有可用处理能力,因此逻辑内核允许更多并行性。
相比之下,我们速度更快的函数只能利用不超过 8 个内核;超过 8 个内核后,速度开始减慢。也许它开始遇到计算以外的瓶颈,比如内存带宽。
对于这两个函数来说,线程池的大小都不是最佳的。
另辟蹊径:实证测量
在获得最佳线程数方面,我们遇到了很多问题:
- 考虑到操作系统限制 CPU 使用的所有不同方式,很难获得准确的内核数量。
- 最佳并行程度(如线程数)取决于工作量。更优化的代码可能无法利用额外的逻辑内核。
- 内核数量并不是唯一的瓶颈。
- 额外的问题:如果你在云中运行,你使用的是 “vCPU”,不管这意味着什么。不同的实例可能有不同的 CPU 型号。
因此,这里有另一种方法:在运行时根据经验发现最佳线程数。在上面的例子中,我们测量了特定代码的最佳线程数。如果你有一个长期运行的数据处理任务,需要在多个线程中运行相同的代码一段时间,你也可以这样做。也就是说,你可以在开始时花一点时间,根据经验测算出最佳线程数,或许还可以使用一些启发式方法来补偿工作量。
就运行时而言,如果您使用的是经验测量法,那么您就不需要关心为什么特定数量的线程是最佳的。无论硬件、操作系统配置或云环境如何,您都将使用最佳并行效果。
本文文字及图片出自 How many CPU cores can you actually use in parallel?