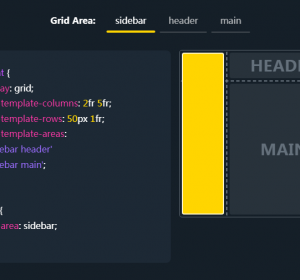
utf8_unicode_ci 和 utf8mb4_0900_ai_ci 之间有什么区别?
在 mysql 中,utf8mb4_0900_ai_ci 和 utf8_unicode_ci 数据库文本编码有什么区别(尤其是在性能方面)?utf8mb4_unicode_ci 和 utf8mb4_0900_ai_ci 之间有类似的区别吗?
总的来说:
- 编码相同。也就是说,字节看起来是一样的。
- 字符集不同。utf8mb4 有更多的字符。
- 校对(进行比较的方式)不同。
- 性能不同,但影响不大。
utf8_unicode_ci 意味着字符集 utf8,它只包含 1、2 和 3 字节的 UTF-8 字符。因此,它不包括大多数 Emoji 和一些汉字。
utf8mb4_unicode_ci 表示字符集 utf8mb4 是 4 字节字符集 utf8mb4 的相应对照组。
多年来,Unicode 组织一直在改进该规范。以下是从其 “版本 “到 MySQL 排序的映射:
4.0 _unicode_
5.2.0 _unicode_520_ (Unicode 2009; MySQL GA 5.6 2013)
9.0 _0900_
14.0 _uca1400_ai_ci etc. as/ai and cs/ci (MariaDB-10.10, not MySQL)大多数差异都出现在大多数人从未接触过的领域。举个例子:在某一时刻,一项更改允许以某种方式对 Emoji 进行区分和排序。
后缀(MySQL 文档):
_bin -- 只比较位;不考虑大小写折叠、重音等
_ci -- 显式不区分大小写(A=a),隐式不区分重音(a=á)
_ai_ci -- 显式不区分大小写,隐式不区分重音
_as (etc) -- 重音敏感(etc)性能:
_bin -- 简单、快速
_general_ci -- 无法比较多个字母;例如,ss=ß,所以有点快
... -- 较慢
_900_ -- (8.0) 由于重写而快得多不过:collation 速度通常是查询中最不重要的性能问题。INDEX、JOIN、子查询、表扫描等对性能的影响更为关键。