如何使用 Node.js 和 Puppeteer 抓取网站
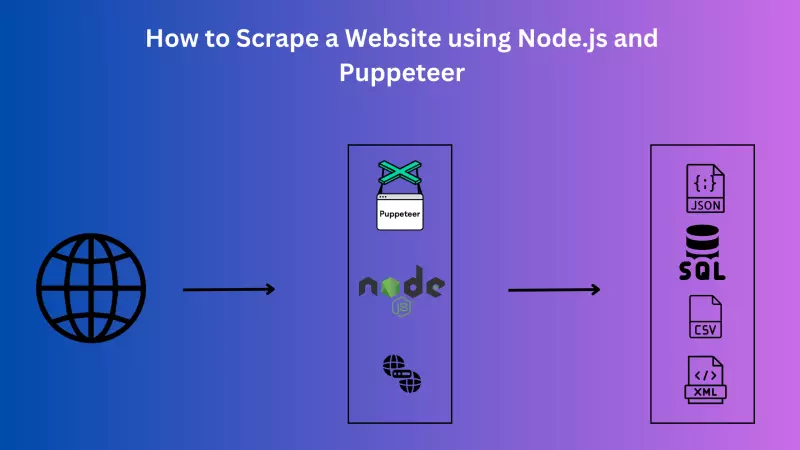
网络抓取是一种功能强大的工具,允许开发人员从网站中提取数据,并将其转换成可用于各种目的的格式。这种技术广泛应用于数据分析、机器学习和市场研究等领域。在处理大量无法以结构化格式随时获取的数据时,它可以大显身手。
Node.js 和 Puppeteer 是两种可用于网络抓取的强大工具。Node.js 是一种 JavaScript 运行环境,允许开发人员在服务器端运行 JavaScript。另一方面,Puppeteer 是一个 Node.js 库,它提供了一个高级 API,可通过 DevTools 协议控制 Chrome 或 Chromium。Puppeteer 对于网络动态内容(即使用 JavaScript 加载或显示数据的网站)的抓取尤其有用。
在本文中,我们将使用 Node.js 和 Puppeteer 从著名的电子商务网站亚马逊抓取数据。亚马逊是一个广受欢迎的网站,由于其数据量巨大且内容具有动态性,因此经常需要进行数据抓取。我们要抓取的数据包括产品详细信息、价格和客户评论。
除了搜索数据,我们还将研究在脚本中使用代理。代理通常用于网络抓取,以绕过诸如速率限制、节流和验证码等网站为防止请求过多而可能使用的障碍。在本文中,我们将使用 Bright Data 的代理,这是一种可靠、高效的网络抓取解决方案。
Node.js 和 Puppeteer:安装和配置
要学习本教程,您需要先设置必要的文件/文件夹并安装所需模块,然后再继续编写代码。
步骤 1:安装 Node.js:要检查计算机上是否已安装 Node.js,请运行以下命令
node - v;
如果您没有安装 Node,可以从这里下载。
第 2 步:设置好 Node.js 后,为您的项目创建一个新文件夹。您可以在终端/命令提示符下运行 mkdir 命令,然后输入文件夹名称。然后使用 cd 命令导航到项目文件夹。
mkdir my-scraper cd my-scraper
第 3 步:运行 npm init 命令,在文件夹中初始化一个新的 Node.js 项目。
npm init -y
步骤 4:接下来,使用下面的命令安装 Puppeteer:
npm install puppeteer
第 5 步:使用你选择的代码编辑器打开项目文件夹。
现在,您已经设置好了项目,可以开始创建刮板了。
使用 Node.js 和 Puppeteer 构建一个简单的网络抓取器
使用 Node.js 和 Puppeteer 构建一个简单的网络抓取器要经过几个步骤。在本节中,我们将以流行的电子商务网站亚马逊为例。
目标网站简介
在开始编写 Puppeteer 脚本之前,了解我们要抓取的网站的结构非常重要。在本例中,我们将抓取亚马逊网站。亚马逊是一个使用 JavaScript 加载和显示数据的动态网站,因此非常适合我们的 Puppeteer 脚本。
编写 Puppeteer 脚本
任务:这里的任务是创建一个基本的 Puppeteer 脚本,用于导航到亚马逊网站、搜索特定商品并提取相关数据。因此,在本例中,你将以搜索输入和搜索按钮元素 id 为目标。
流程如下:
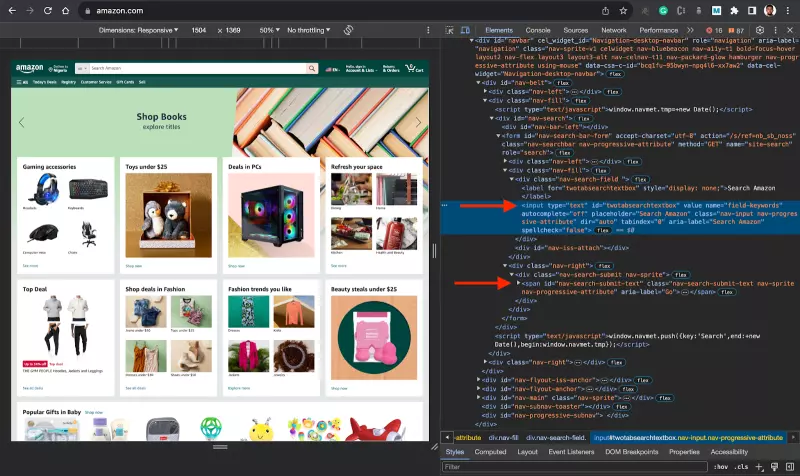
之后,您想在页面加载时搜索特定项目(笔记本电脑),您想在搜索结果中获得项目的标题和价格。
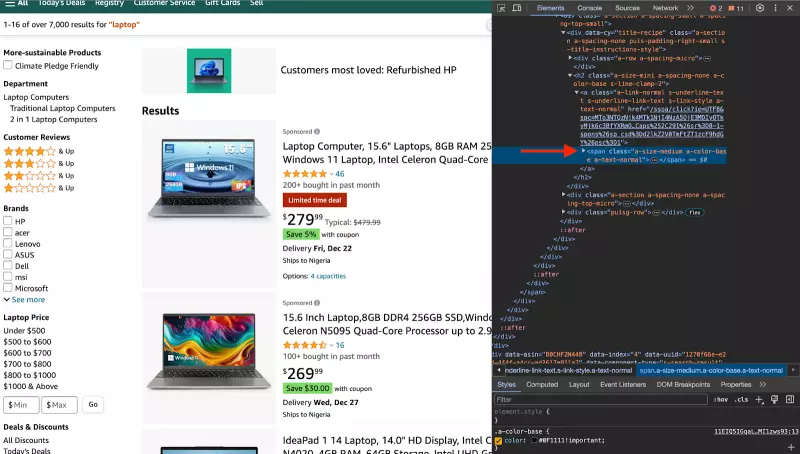
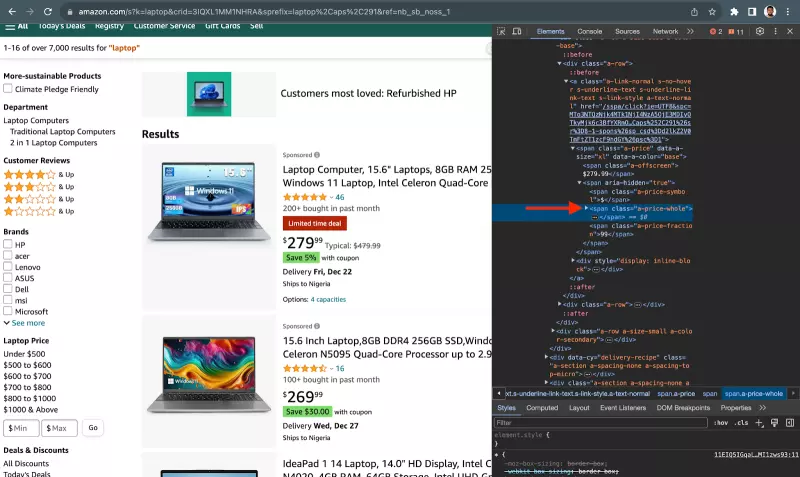
要在代码中实现这一点,请在 my-scraper 文件夹中为脚本创建一个名为 index.js 的新文件,并执行下面的代码。
const puppeteer = require(''puppeteer'');
async function run() {
// browser = await puppeteer.connect({ browserWSEndpoint: SBR_WS_ENDPOINT });
browser = await puppeteer.launch({ headless: ''old'' });
try {
const page = await browser.newPage();
// Navigate to Amazon
await page.goto(''https://www.amazon.com/'', {
waitUntil: ''networkidle2'',
timeout: 30000,
});
await page.waitForSelector(''#twotabsearchtextbox'', { timeout: 5000 });
// Search for a specific item
await page.type(''#twotabsearchtextbox'', ''laptop'', {
delay: 100,
}); // Modify this to your desired search term
await page.click(''#nav-search-submit-button'');
await page.waitForSelector(''[data-component-type="s-search-result"]'', {
timeout: 5000,
});
const searchResults = await page.$$(
''[data-component-type="s-search-result"]''
);
await new Promise(r => setTimeout(r, 10000));
const results = [];
for (const result of searchResults) {
// Process each result as needed, for example:
const title = await result.$eval(
''div[data-cy="title-recipe"] h2 a span.a-size-medium.a-color-base.a-text-normal'',
(el) => el.textContent
);
const price = await result.$eval(
''.a-price span.a-offscreen'',
(el) => el.textContent
);
results.push({
title,
price,
});
}
console.log(results);
await browser.close();
} catch (error) {
console.error(''Error during execution:'', error);
} finally {
// Close the browser
if (browser) {
await browser.close();
}
}
}
// Call the run function
run();
上面的代码是一个简单的网络抓取器,它使用 Node.js 和 Puppeteer 从亚马逊抓取数据。该脚本旨在搜索特定商品(本例中为 “笔记本电脑”),并提取每个搜索结果的标题和价格。
下面是代码的逐步说明:
- 导入 Puppeteer:脚本首先导入 Puppeteer 库,该库提供了控制无头浏览器所需的功能。
const puppeteer = require(''puppeteer'');
- 启动浏览器:接下来,脚本会启动一个新的浏览器实例。
headless: ‘old’选项用于控制浏览器是否以无头模式运行。
browser = await puppeteer.launch({ headless: ''old'' });
- 导航到亚马逊:然后,脚本使用
page.goto()函数导航到亚马逊网站。waitUntil:networkidle2'和timeout:30000选项用于确保页面完全加载后再继续。
await page.goto(''https://www.amazon.com/'', {
waitUntil: ''networkidle2'',
timeout: 30000,
});
搜索特定项目:然后,脚本在搜索框中输入特定的搜索词,并提交搜索表单。
await page.type(''#twotabsearchtextbox'', ''laptop'', {
delay: 100,
}); // Modify this to your desired search term
await page.click(''#nav-search-submit-button'');
- 提取搜索结果:加载搜索结果后,脚本会提取每个结果的标题和价格。这需要使用
page.$$()函数选择所有搜索结果,然后使用result.$eval()函数提取每个结果的标题和价格。
const searchResults = await page.$$(''[data-component-type="s-search-result"]'');
const results = [];
for (const result of searchResults) {
const title = await result.$eval(
''div[data-cy="title-recipe"] h2 a span.a-size-medium.a-color-base.a-text-normal'',
(el) => el.textContent
);
const price = await result.$eval(
''.a-price span.a-offscreen'',
(el) => el.textContent
);
results.push({
title,
price,
});
}
- 记录结果:最后,脚本会将提取的数据记录到控制台。.
console.log(results);
- 关闭浏览器:然后,脚本使用 browser.close() 函数关闭浏览器。
await browser.close();
本脚本是如何使用 Puppeteer 从网站抓取数据的一个简单示例。它演示了网络抓取的基本步骤,包括导航到网页、与网页交互(在本例中是通过执行搜索)以及从网页中提取数据。
运行 node script.js 时,应该会得到以下格式的输出结果

不过,运行这个脚本可能会遇到一些问题。例如,如果来自同一 IP 地址的请求过于频繁,亚马逊可能会阻止您的请求。这是一个常见问题,被称为 IP 禁止。您的脚本中可能会开始出现这样的错误:
 或者
或者
 另一个潜在问题是频率限制。有些网站会限制一定时间内的请求次数。如果我们超过了这个限制,您的请求就会被阻止。为缓解这一问题,你可以使用新的
另一个潜在问题是频率限制。有些网站会限制一定时间内的请求次数。如果我们超过了这个限制,您的请求就会被阻止。为缓解这一问题,你可以使用新的 Promise(r => setTimeout(r, 10000)); 来暂停脚本执行一段指定的时间(如果 10 秒不够,你可以增加脚本暂停的时间)。
await new Promise((r) => setTimeout(r, 10000));
有些网站还使用验证码CAPTCHAs来验证用户是否为人类。这对网络抓取程序来说是一个巨大的挑战,因为验证码的设计使自动系统难以解决。
使用代理可以避免这些挑战。在下一节中,您将了解更多关于代理的信息,并亲眼目睹代理的实际应用。
使用代理处理常见的抓取难题
开发人员利用代理来克服上一节中提到的挑战。代理允许通过多个 IP 地址发出请求,因此在抓取中发挥着关键作用。这有助于克服网站为防止自动访问而设置的 IP 禁止和速率限制等限制。此外,代理服务器还可以掩盖搜索者的身份,增强匿名性,降低被拦截的可能性,从而有助于避免被发现。
有多种代理服务器可供您选择。不过,在本节中,我们将使用 Bright Data 的代理作为上述挑战的解决方案。Bright Data 的代理服务器是收费的。它们可靠、快速,并具有自动 IP 轮换和验证码解锁等功能,可以帮助避免拦截并提高搜索过程的效率。

此外,Bright Data 还提供各种类型的代理服务器,包括住宅代理服务器、移动代理服务器、数据中心代理服务器和 ISP 代理服务器,使其适用于不同的应用。它还能自动轮换 IP 地址,这对网络抓取应用特别有用。每次用户发出连接请求时,IP 地址都会改变,以减少过度使用任何单一 IP 的可能性。
综上所述,让我们来看看如何将 Bright Data 的代理服务器集成到您的搜索脚本中。
如何将 Bright Data 整合到您的脚本中
要将 Bright Data 的代理集成到我们之前的抓取代码中,我们需要遵循几个步骤:
注册 – 访问 Bright Data 主页并点击 “开始免费试用”。如果您已经拥有 Bright Data 账户,则可以登录。
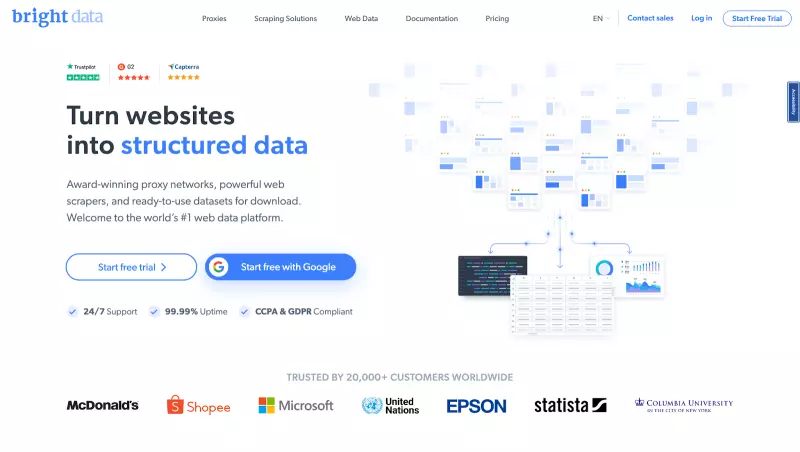
- 输入详细信息并完成注册过程后,您将被重定向到欢迎页面。在那里,点击 “View Proxy Products“。
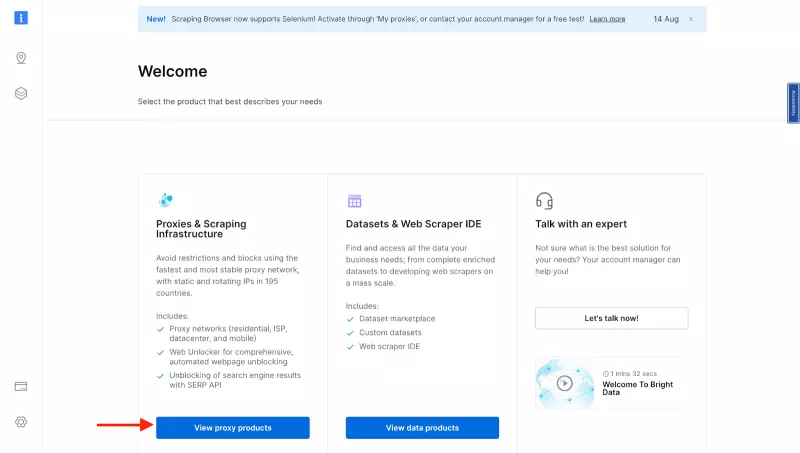
- 您将进入 “Proxies & Scraping Infrastructure “页面。在 “My proxies “下,单击 “Residential Proxie “卡上的 “Get started””。
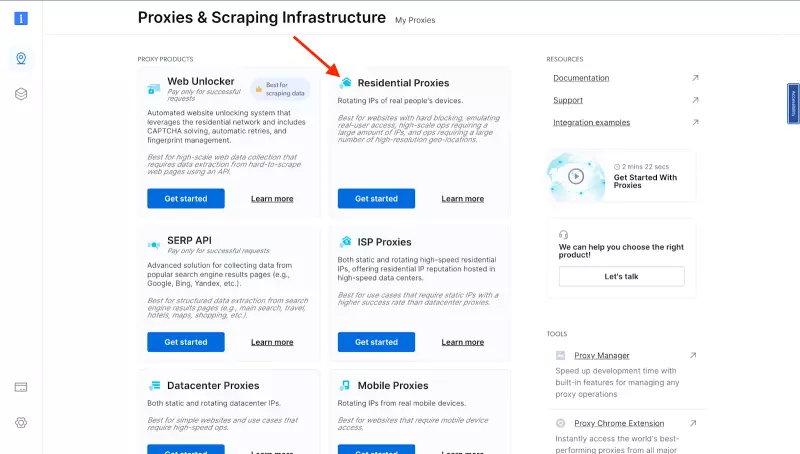
- 如果您已经有一个活动代理,只需单击 “Add “并选择 “Residential Proxies“。注意:您可以根据自己的需要选择任何代理选项。
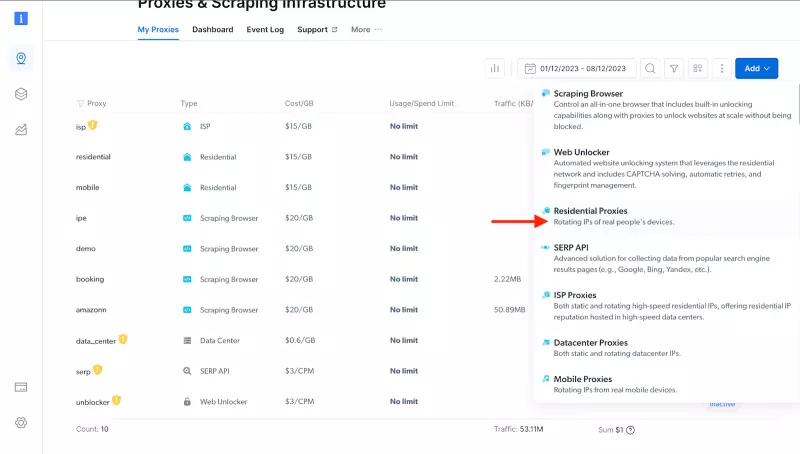
- 接下来,您将进入 “Add new proxy solution “页面,在这里您需要为新的住宅代理区域选择名称和 IP 类型。然后,点击 “Save and activate“或 “Add“。
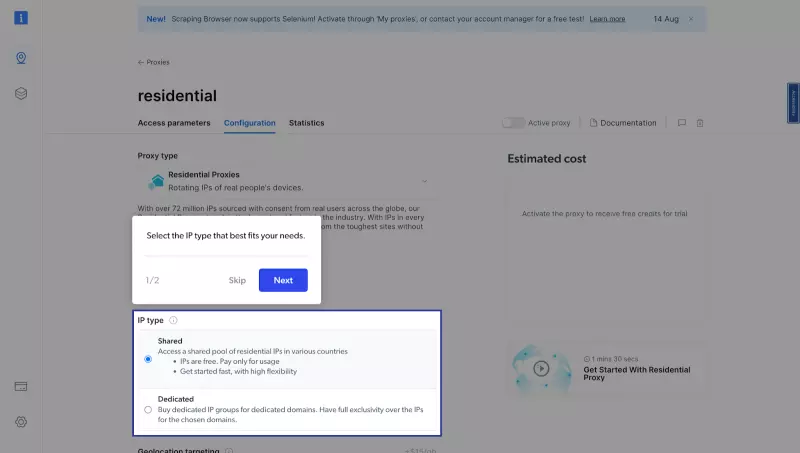
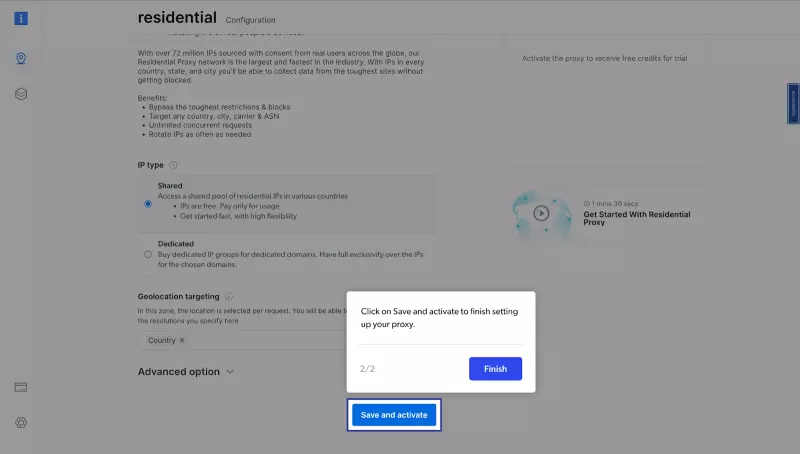
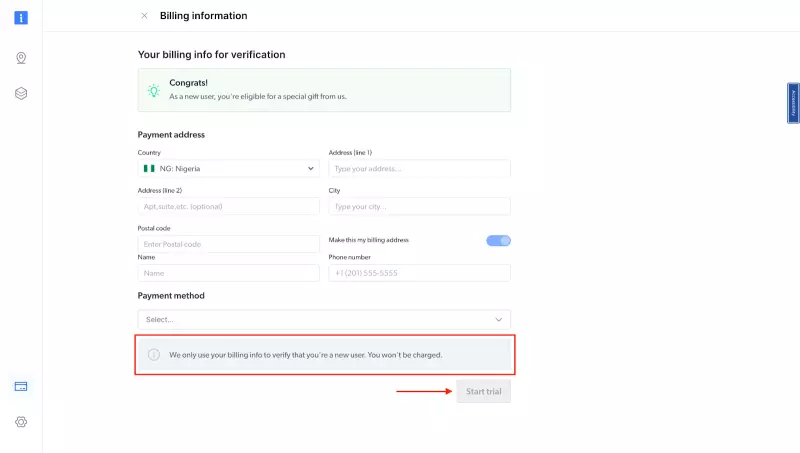
- 此时,如果您尚未添加付款方式,系统会提示您添加付款方式以验证您的账户。作为 Bright Data 的新用户,您将收到 5 美元的奖励积分,以便开始使用。
注意:这主要是为了验证目的,此时不会向您收取费用。
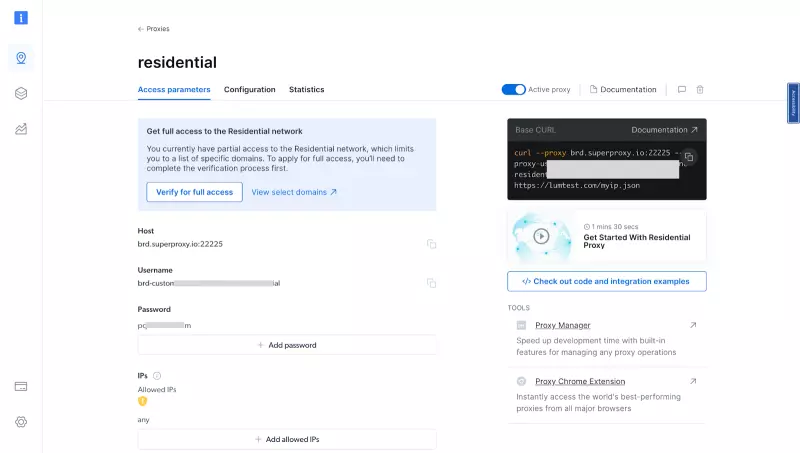
- 验证账户后,将创建代理区域。
配置 Bright Data 代理
现在,您可以将 Bright Data 的代理集成到之前的抓取代码中,我们需要遵循几个步骤。
- 获取 Bright Data 代理凭证:现在您已经创建了代理,请获取您的代理凭据,因为您需要在脚本中使用这些凭据(用户名和密码)。
- 将 Bright Data 的 IP 整合到抓取脚本中:获得代理证书后,您就可以将其整合到您的搜索脚本中。这通常需要在 Puppeteer 启动选项中设置代理。
const puppeteer = require(''puppeteer'');
async function run() {
browser = await puppeteer.launch({ headless: ''true'' });
try {
const page = await browser.newPage();
await page.authenticate({
username: ''paste your proxy username here'',
password: ''<paste your proxy password here'',
host: ''<paste your proxy host here'',
});
// Navigate to Amazon
await page.goto(''https://www.amazon.com/'', {
waitUntil: ''networkidle2'',
timeout: 30000,
});
await page.waitForSelector(''#twotabsearchtextbox'', { timeout: 5000 });
// Search for a specific item
await page.type(''#twotabsearchtextbox'', ''laptop'', {
delay: 100,
}); // Modify this to your desired search term
await page.click(''#nav-search-submit-button'');
await page.waitForSelector(''[data-component-type="s-search-result"]'', {
timeout: 5000,
});
const searchResults = await page.$$(
''[data-component-type="s-search-result"]''
);
await new Promise((r) => setTimeout(r, 10000));
const results = [];
for (const result of searchResults) {
// Process each result as needed, for example:
const title = await result.$eval(
''div[data-cy="title-recipe"] h2 a span.a-size-medium.a-color-base.a-text-normal'',
(el) => el.textContent
);
const price = await result.$eval(
''.a-price span.a-offscreen'',
(el) => el.textContent
);
results.push({
title,
price,
});
}
console.log(results);
await browser.close();
} catch (error) {
console.error(''Error during execution:'', error);
} finally {
// Close the browser
if (browser) {
await browser.close();
}
}
}
// Call the run function
run();
脚本做了哪些改动?
const page = await browser.newPage();
await page.authenticate({
username: ''paste your proxy username here'',
password: ''paste your proxy password here'',
host: ''paste your proxy host here'',
});
page.authenticate 方法用于使用从 Bright Data 获取的代理凭据验证页面。该方法接收一个包含用户名、密码和主机属性的对象。用户名和密码是代理凭据,主机是代理服务器。
- 再次运行抓取脚本:集成代理后,您可以再次运行搜索脚本。这次,请求将从不同的 IP 地址发出,这有助于避免我们之前遇到的问题。
下面是输出结果:
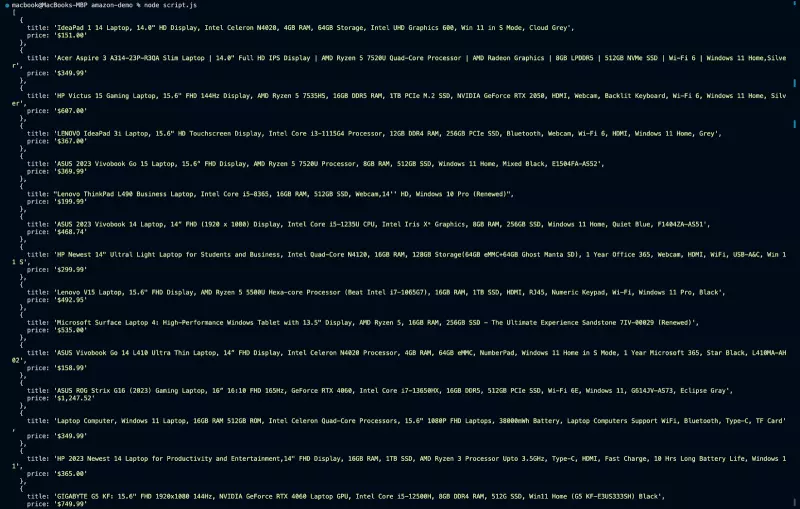
现在,无论你如何运行脚本,都不会再出现之前遇到的错误了。因此,通过使用代理,我们可以确保网络搜索活动更加高效、无缝和可靠。
有关 Bright Data 代理的更多信息,请参阅官方文档。
结论
网络抓取是一种功能强大的工具,可以提供有关市场趋势、客户偏好和竞争对手动向的宝贵信息。不过,它也有自己的一系列挑战,如 IP 禁止、速率限制和验证码。使用代理可以减轻这些挑战,代理允许我们从不同的 IP 地址发出请求,从而避免 IP 禁止和绕过频率限制。
在本文中,我们探讨了如何使用 Node.js 和 Puppeteer 进行网络抓取,以及如何使用 Bright Data 的代理处理常见的抓取难题。
通过使用代理,我们可以确保网络抓取活动更加高效可靠。总之,使用 Node.js、Puppeteer 和 Bright Data 的代理进行网络抓取是一种从网站收集数据的强大而高效的方法。通过了解网络抓取带来的挑战并知道如何应对这些挑战,您就能充分利用这一强大的工具。